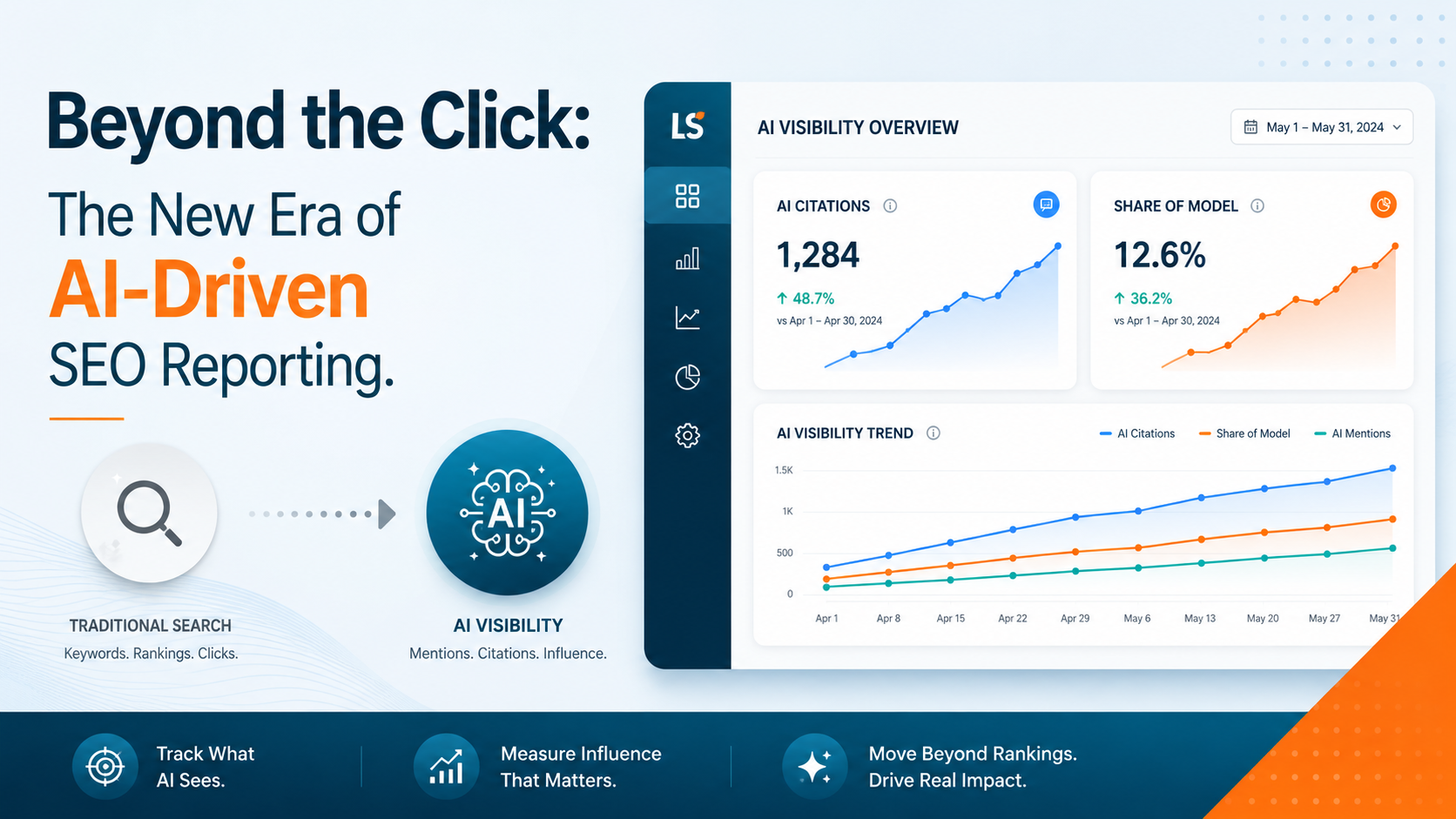
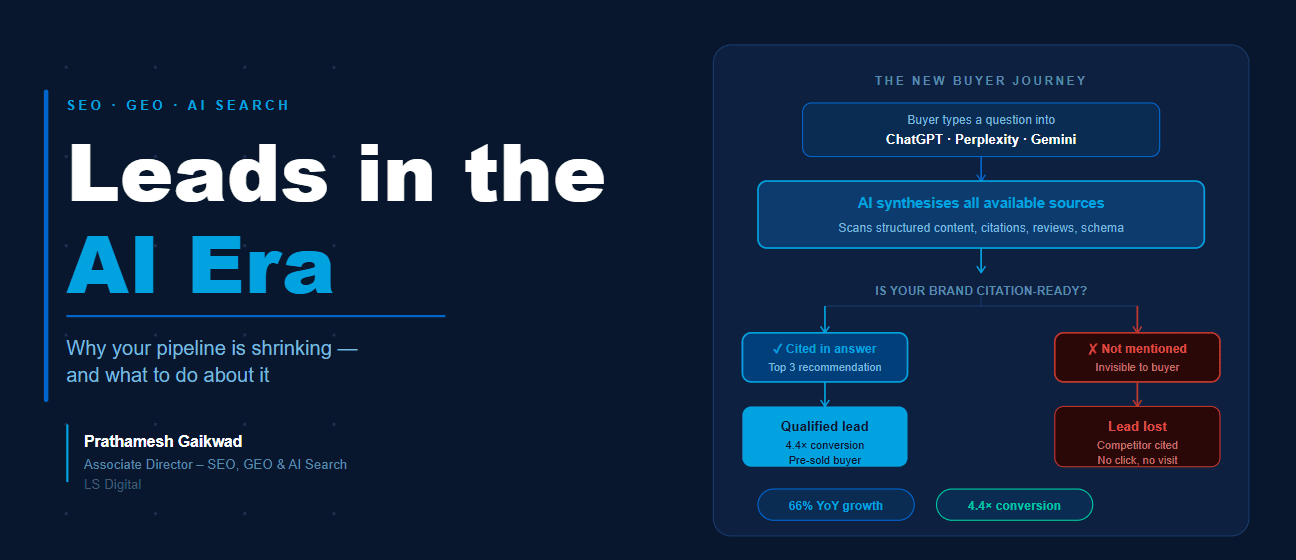
To perform search engine optimisation, web crawlers play a pivotal role. A web crawler (also known as a web spider or search engine robot) is a programmed script that browses the World Wide Web in a methodical, automatic manner. This process is called as web crawling or spidering.
Search engines and many web sites make use of crawling as a means of providing the latest data. Web crawlers are generally used to create a copy of all the visited pages for subsequent processing by the search engine that will index the downloaded pages to facilitate fast searches. To put it simply, the web crawler or web spider is a type of bot, or a software program that visits web sites and reads their pages and other information to create entries for a search engine index.
When the web spider returns home, the data is indexed by the search engine. All the main search engines, such as Google and Yahoo, use spiders to build and revise their indexes.
Moreover, the spiders or crawlers are used for automating maintenance tasks on the web site. For example, the crawlers are used to validate HTML code, gather certain types of data from the web sites, and check links on the web page to other sites.
Furthermore, what the crawler sees on a web site will determine how the site is listed in its index. The search engines find out a web site’s relevancy based on an intricate scoring system, which they try to keep secret